页面置换算法之Clock算法
页面置换算法之Clock算法
1.前言
缓冲池是数据库最终的概念,数据库可以将一部分数据页放在内存中形成缓冲池,当需要一个数据页时,首先检查内存中的缓冲池是否有这个页面,如果有则直接命中返回,没有则从磁盘中读取这一页,然后缓存到内存并返回。
但是内存的价值较高,一般来说服务器的内存总是小于磁盘大小的,而且内存不能完全分配给数据库作为缓冲池。这就意味着数据库基本上无法将所有的数据都缓冲到内存中。
当缓冲池满后,如果还有新的页面要被缓冲到池中,就要设计一种页面置换的算法,将一个旧的页面替换成新的页面。
一般来说我们熟悉的算法有下面几种:
下面逐一介绍各种算法。
2. 最佳置换算法
如果被替换掉的页是以后再也不会使用的,那么这种算法无疑是最优秀的。因为不管什么算法,替换掉的页也有可能再次被缓存,替换掉其它的页。
但是这种算法是无法实现的,我们不可能知道哪个页面以后也在不会被使用。
或者我们退一步,将这个算法改成被替换掉的页是以后很长一段时间都不会再次被使用的,那么这种算法无疑也是最优秀的。
但是还是会面对一个无法实现的问题,我们还是不知道哪些页面会在未来多长一段时间内不会被再次访问。页面无法确认,时间也无法确定。
虽然这种算法无法被实现,但是可以作为一种度量,如果有一种算法其效率最接近OPT,那么这种算法无疑是优秀的算法。
3. 先进先出算法
先进先出算法是一种很简单的算法,其基本思想是形成一个队列,最先入队的页面最先被逐出。我们用示意图来模拟一下FIFO算法:
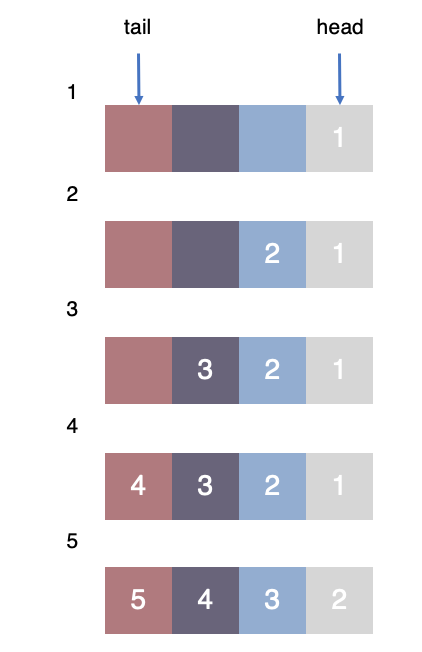
我们的内存假设只能保存4个页面,此时的访问请求按照时间顺序是1->2->3->4->5,那么按照时间顺序,当访问到4号页面时队列正好填满,当要访问5号页面时,会将最先入队的1号页面逐出。
这种算法实现起来很简单,但是从实现上来看,性能和OPT算法差距最大。因为被替换出去的页面很有可能是最常使用的页面,因此这个算法很少见出现在数据库缓冲池管理中的。
FIFO算法会出现一个叫做Belay异常的现象,就这个现象我们解释如下。
我们首先定义一个4个页面长度的队列作为缓冲池,然后按照下面的顺序访问:1->2->3->4->5->3->9->1->4->2->7->4->7。那么我们按照刚才描述的FIFO来看看访问的过程:
| 访问顺序 | 访问页 | 内存队列 | 是否命中 |
|---|---|---|---|
| 1 | 1 | 1 | 否 |
| 2 | 2 | 1,2 | 否 |
| 3 | 3 | 1,2,3 | 否 |
| 4 | 4 | 1,2,3,4 | 否 |
| 5 | 5 | 2,3,4,5 | 否 |
| 6 | 3 | 2,3,4,5 | 是 |
| 7 | 9 | 3,4,5,9 | 否 |
| 8 | 1 | 4,5,9,1 | 否 |
| 9 | 4 | 4,5,9,1 | 是 |
| 10 | 2 | 5,9,1,2 | 否 |
| 11 | 7 | 9,1,2,7 | 是 |
| 12 | 4 | 1,2,7,4 | 否 |
| 13 | 7 | 1,2,7,4 | 是 |
从这个表格上看到,非命中次数有9次,那么我们将这个队列的容量增加到5,然后再次重复这个访问序列,看看效果:
| 访问顺序 | 访问页 | 内存队列 | 是否命中 |
|---|---|---|---|
| 1 | 1 | 1 | 否 |
| 2 | 2 | 1,2 | 否 |
| 3 | 3 | 1,2,3 | 否 |
| 4 | 4 | 1,2,3,4 | 否 |
| 5 | 5 | 1,2,3,4,5 | 否 |
| 6 | 3 | 1,2,3,4,5 | 是 |
| 7 | 9 | 2,3,4,5,9 | 否 |
| 8 | 1 | 3,4,5,9,1 | 是 |
| 9 | 4 | 3,4,5,9,1 | 是 |
| 10 | 2 | 4,5,9,1,2 | 否 |
| 11 | 7 | 5,9,1,2,7 | 否 |
| 12 | 4 | 9,1,2,7,4 | 否 |
| 13 | 7 | 9,1,2,7,4 | 否 |
这样的话,非命中的次数是10次,奇怪的是增加了缓冲池的容量,非命中缓冲的数量还增加了,这种现象就叫做Belay异常。
这种算法不应该被考虑。
4. 最近最少使用算法
LRU算法的思想也很简单,实现一个链表(双向链表),每次要缓冲新的页面时,遍历链表,选择最近最少使用的页面进行逐出操作。
这种算法要求每个页面上记录一个上次使用时间t,程序决定逐出时,以这个时间t为准,t距离当前时间最大的,就是要被逐出的页面。
下图中按照1->5->2->2->6->5->4的顺序访问,内存和访问示意图如下:
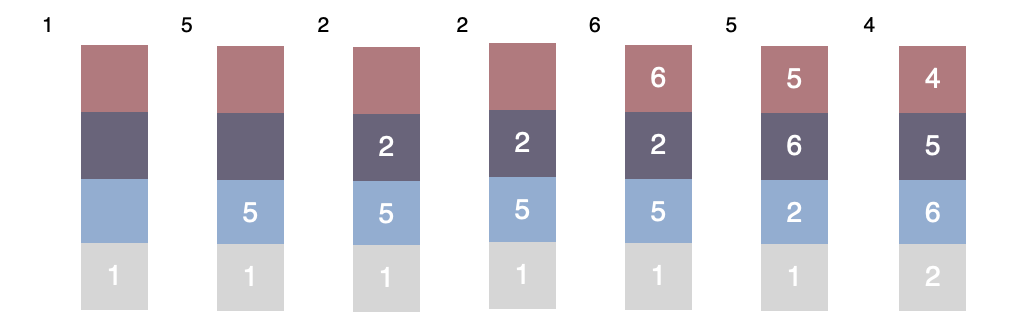
其中最接近顶端的页面我们认为其t最小,最接近底部,我们认为其t最大。
访问6号页面的时候,内存被填满,下一次访问5号页面的时候,会将5号页面提升到顶部,也就是t最小,之后访问4号页面,因为原先内存中没有4号页面,因此会选择逐出一个页面。此时1号页面在底部,其t最大,因此被逐出。
那么LRU算法是否解决了Belay异常呢?
还是按照上一节的实验顺序,测试容量为4和5的内存,左侧到右侧,t逐渐增大:
| 访问顺序 | 访问页 | 内存队列 | 是否命中 |
|---|---|---|---|
| 1 | 1 | 1 | 否 |
| 2 | 2 | 1,2 | 否 |
| 3 | 3 | 1,2,3 | 否 |
| 4 | 4 | 1,2,3,4 | 否 |
| 5 | 5 | 2,3,4,5 | 否 |
| 6 | 3 | 2,4,5,3 | 是 |
| 7 | 9 | 4,5,3,9 | 否 |
| 8 | 1 | 5,3,9,1 | 否 |
| 9 | 4 | 3,9,1,4 | 否 |
| 10 | 2 | 9,1,4,2 | 否 |
| 11 | 7 | 1,4,2,7 | 否 |
| 12 | 4 | 1,2,7,4 | 是 |
| 13 | 7 | 1,2,4,7 | 是 |
一共有10次未命中。增加容量到5,看一下新的情况:
| 访问顺序 | 访问页 | 内存队列 | 是否命中 |
|---|---|---|---|
| 1 | 1 | 1 | 否 |
| 2 | 2 | 1,2 | 否 |
| 3 | 3 | 1,2,3 | 否 |
| 4 | 4 | 1,2,3,4 | 否 |
| 5 | 5 | 1,2,3,4,5 | 否 |
| 6 | 3 | 1,2,4,5,3 | 是 |
| 7 | 9 | 2,4,5,3,9 | 否 |
| 8 | 1 | 4,5,3,9,1 | 否 |
| 9 | 4 | 5,3,9,1,4 | 是 |
| 10 | 2 | 3,9,1,4,2 | 否 |
| 11 | 7 | 9,1,4,2,7 | 否 |
| 12 | 4 | 9,1,2,7,4 | 是 |
| 13 | 7 | 9,1,2,4,7 | 是 |
未命中的次数已经变成了9次,减少了一次,如果我设计的队列中有大量的重复,那么这个改进应该更加明显。
LRU算法在InnoDB的实现中是被改进的,每次新添加进去的页面会被放在队列的3/8处。
无论如何,LRU算法都被认为是最接近OPT的算法。
5. 时钟置换算法
时钟置换算法可以认为是一种最近未使用算法,即逐出的页面都是最近没有使用的那个。我们给每一个页面设置一个标记位u,u=1表示最近有使用u=0则表示该页面最近没有被使用,应该被逐出。
按照1-2-3-4的顺序访问页面,则缓冲池会以这样的一种顺序被填满:
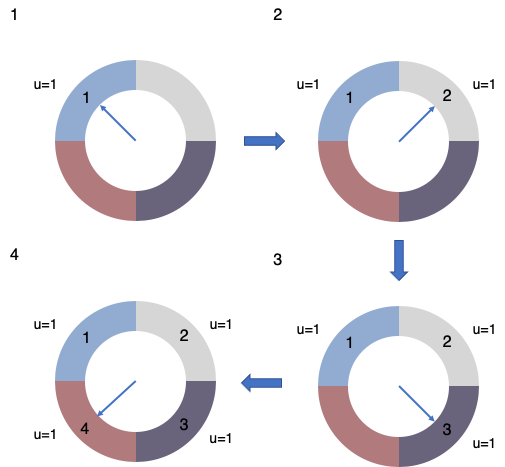
注意中间的指针,就像是时钟的指针一样在移动,这样的访问结束后,缓冲池里现在已经被填满了,此时如果要按照1-5的顺序访问,那么在访问1的时候是可以直接命中缓存返回的,但是访问5的时候,因为缓冲池已经满了,所以要进行一次逐出操作,其操作示意图如下:
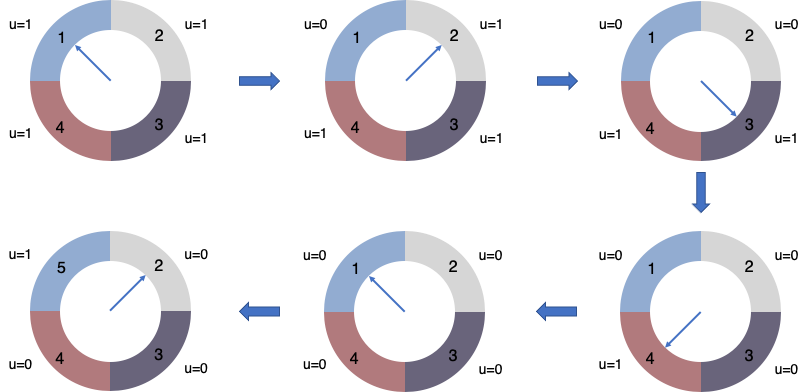
最初要经过一轮遍历,每次遍历到一个节点发现u=1的,将该标记位置为0,然后遍历下一个页面,一轮遍历完后,发现没有可以被逐出的页面,则进行下一轮遍历,这次遍历之后发现原先1号页面的标记位u=0,则将该页面逐出,置换为页面5,并将指针指向下一个页面。
假设我们接下来会访问2号页面,那么可以直接命中指针指向的页面,并将这个页面的标记为u置为1。
但是考虑一个问题,数据库里逐出的页面是要写回磁盘的,这是一个很昂贵的操作,因此我们应该优先考虑逐出那些没有被修改的页面,这样可以降低IO。
因此在时钟置换算法的基础上可以做一个改进,就是增加一个标记为m,修改过标记为1,没有修改过则标记为0。那么u和m组成了一个元组,有四种可能,其被逐出的优先顺序也不一样:
- (u=0, m=0) 没有使用也没有修改,被逐出的优先级最高;
- (u=1, m=0) 使用过,但是没有修改过,优先级第二;
- (u=0, m=1) 没有使用过,但是修改过,优先级第三;
- (u=1, m=1) 使用过也修改过,优先级第四。
评论已关闭